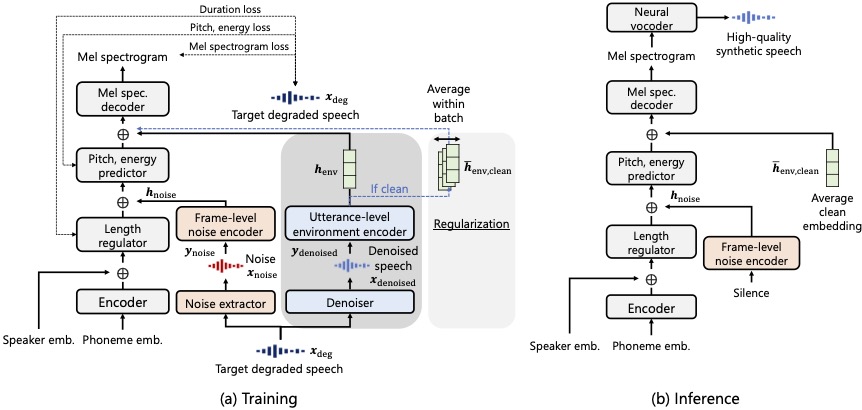
Most text-to-speech (TTS) methods use high-quality speech corpora recorded in a well-designed environment, incurring a high cost for data collection. To solve this problem, existing noise-robust TTS methods are intended to use noisy speech corpora as training data. However, they only address either time-invariant or time-variant noises. We propose a degradation-robust TTS method, which can be trained on speech corpora that contain both additive noise and environmental distortion. It jointly represents the time-variant additive noise with a frame-level encoder and the time-invariant environmental distortion with an utterance-level encoder. We also propose a regularization method to attain clean environmental embedding that is disentangled from the utterance-dependent information such as linguistic contents and speaker characteristics. Evaluation results show that our method achieved significantly higher-quality synthetic speech than previous methods in the condition including both additive noise and reverberation.
Audio samples
Clean GT: Ground-truth clean speech samples.
Degraded GT: Ground-truth degraded speech samples used for the training data.
Enhancement TTS: Normal TTS model trained on enhanced target speech (correspond to [1]).
Noise-Robust TTS: Noise-robust TTS model using frame-level noise representation (correspond to [2]).
DRSpeech: Proposed degradation-robust TTS method.
DRSpeech w/o regularization: Proposed degradation-robust TTS without a regularization method.